Stage 2 — Building Enterprise-Aware AI Agent Capability with Mule & MCP
Introduction: Unpacking MCP
In this workshop module, you will give your LLM powered AI agent access to real-time enterprise data by implementing Model Context Protocol (MCP) integrations.
The Model Context Protocol (MCP) is an open standard that allows AI agents to interact with external databases, APIs, and business systems in a structured way.
MuleSoft MCP Connector uses this standard to expose existing Anypoint Platform integrations as actionable resources for AI. By using the MCP Connector and its associated Listener, developers can transform their current APIs into tools that agents can understand and invoke directly. This is especially useful for giving an agent "live" capabilities, such as allowing it to check a shipping status or update a customer record through a pre-existing MuleSoft flow.
Large Language Models include a feature called Function Calling. Function calling allows an LLM to step outside its static training by signaling the need for a specific "tool," such as a database query or an API call. Because the model cannot physically execute these actions itself, it instead signals its intent by including specific instructions in its response - developers must run the requested action and return the result to the model.
This concept is the technical foundation for how the Model Context Protocol (MCP) functions. While the Large Language Model provides the reasoning to decide which tool is needed, the Mule MCP connector allows those APIs to communicate using the protocol, effectively turning business logic into an actionable tool. This setup ensures that when an agent expresses the intent to perform a specific business action, the system can use the underlying MuleSoft integration to execute that task and return the result to the model.
Our Workshop Project

In this stage, you will build a core agentic capability using MuleSoft—not a fully autonomous agent. The focus is on implementing the reasoning and grounding mechanism that modern AI agents rely on, in a way that can later be embedded into different architectures and user experiences.
You will create a Mule-based capability that combines:
- A Groq-hosted large language model (LLM)
- The MuleSoft Inference Connector (using its chat and MCP client features)
- A Mule MCP Connector that exposes an enterprise knowledge source as an MCP server
In Stage 1, you implemented an LLM-powered capability that can reason over prompts and generate responses, but which relies entirely on pre-trained model knowledge and prompt context. In Stage 2, you take the next maturity step by grounding that reasoning in authoritative, external knowledge.
This stage introduces the concept of authoritative knowledge sources and demonstrates how AI-driven systems dynamically consult them at runtime, rather than attempting to “remember” or embed all information inside the model itself. The capability you build will decide when external information is required, retrieve it through MCP, and incorporate it into the final response.
By the end of Stage 2, you will have implemented the foundational building block of a real agent: a reusable, headless reasoning-and-action capability that can answer questions using live, authoritative enterprise information—rather than relying solely on static training data, web searches, or general reasoning.
Hands-on: Building the MCP powered Agent
To save time, instead of assembling the flows component-by-component, we’ve provided packaged JAR files in which the key steps have already been completed. You’ll import it into Anypoint Studio, run it locally, and deploy it to CloudHub. This section walks you through the entire process end-to-end—from import to deployment and testing.
Although you are using a pre-packaged JAR rather than configuring each connector manually in Anypoint Studio, we still explain every part of it in the sections below, so you understand exactly how it works and how to apply the same approach in your own projects.
Stage 2a — Build the Knowledge Authority (MCP Server)
The first step is to build and deploy a Model Context Protocol (MCP) server. The MCP server represents an authoritative knowledge source that lives outside the agent. It exposes information such as advisories, updates, notices, or reference catalogs that may change frequently and should not be statically indexed.
In this workshop, the MCP server is backed by a simple Gist document and deployed to CloudHub. The key idea is not the data itself, but the pattern: the MCP server exists independently, can be queried on demand, and acts as a source of truth for latest or real-time information.
At this point, no agent is involved yet. You are intentionally building the knowledge authority first.
Open up your VM (instructions provided by your instructor). All the following hands-on steps are to be completed inside the VM.
MCP Server
Download the packaged JAR file (use chrome browser): Download MCP Server JAR
Typically it will download the file in the following locations inside the VM: C:\Users\workshop\Downloads
Click on File → Import and find the downloaded JAR (stage2_customer_mcp-server-v1.jar) on your VM.

Choose the import wizard → Anypoint Studio → Packaged Application
You can monitor the import progress in the bottom right corner of the Anypoint Studio.
Once import completes, a project gets created in Anypoint Studio with the configurations packaged in the JAR file.
In Mule Anypoint Studios’ left sidebar, find the file src/main/mule/mcp-server-v1.xml as shown in the diagram below.

It will open the main flow of this stage 2a MCP Server Mule ‘app.'
How is this Mule app calling the source database so it can expose it as a MCP server? Click on the Request element in the flow as shown in the following screenshot.

You will see the referenced URL that points to our Gist document source database.
When a user makes a request to an agent (i.e., the MCP client), this inference connector’s HTTP Request connector makes a REST call to the GIST document, fetches the content and serves it back.
Right click on the project in the left sidebar → Run As → Mule Application

When the run completes successfully you should see a ‘Deployed’ message in the bottom screen.

Test your locally deployed MCP server using a Windows shell:
curl http://localhost:8082/healthExpected response:
{ "status": "ok", "service": "mcp-authoritative-server"}curl -N http://localhost:8081/sseThis should establish an SSE connection (Server-Sent Events). You'll see a hanging connection - that's normal for SSE.

Now that we know the MCP server is working great locally, let’s now deploy the MCP Server to Mule CloudHub.
In Mule Anypoint Studio, in left sidebar, right click your project → Anypoint Platform → Deploy to CloudHub
It will bring up a browser window inside your Anypoint Studio - authenticate with your Mule trial username. Select No for creating a password hint.
After sign-in, go back to your project - Right Click → Anypoint Platform → Deploy to CloudHub - select Sandbox
In the Runtime Manager dialog box, change the name to “stage2-customer-mcp-server” so it conforms to CloudHub requirements.

Press Deploy Application button.
Now go to MuleSoft.com sign-in with your Mule trial account. Click on Runtime Manager.
When the deployment finishes, you should see your MCP server status as running.
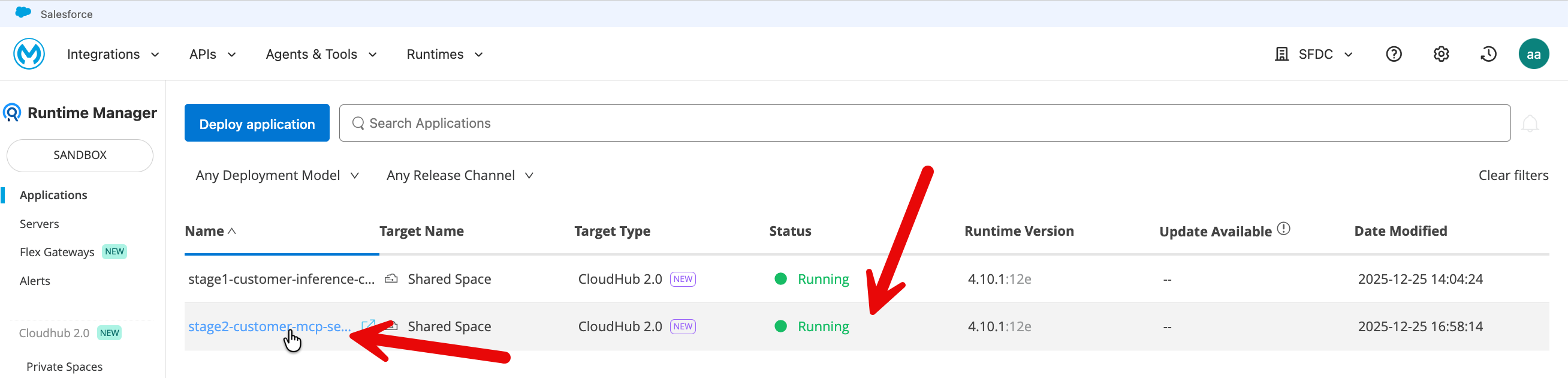
Click on your application and copy the public endpoint (top right on the application page).
Test your deployed MCP server using the following tester: https://mcp-client-tester-fa6774d469ee.herokuapp.com/

Let’s also test your MCP server from CURL.
From your Windows shell, test your MCP server deployed on Mule Cloudhub (replace the URL with your public endpoint in the following commands).
curl -N https://your-app-name.us-e1.cloudhub.io/sse
This should establish an SSE connection (Server-Sent Events). You'll see a hanging connection - that's normal for SSE.
Monitor in CloudHub: Navigate to Runtime Manager → Your Application → Logs. Review the logs to confirm the application has started successfully and to check for any errors or connection issues.
Stage 2b — Connect the Agent to Real-Time Authority
Next, you upgrade the custom agent from Stage 1 by wiring it to the MCP server using the Mule Inference Connector’s MCP client. The agent itself does not change its role — it still reasons, synthesizes, and responds — but it now has the ability to ask an external authority for fresh information when needed.
When a user asks a question that implies latest, current, or recent information, the agent queries the MCP server and incorporates that response into its answer. This happens dynamically at runtime, ensuring that answers reflect the most up-to-date context available.
The following few steps of downloading and then importing the JAR file are very similar to what you did for the previous stage 2a above.
Download the packaged JAR file (use chrome browser): Download Client JAR
Typically it will download the file in the following locations inside the VM: C:\Users\workshop\Downloads
Click on File → Import and find the file the downloaded JAR (stage2b-customer-inference-chat-mcpclient.jar) on your VM.
Choose the import wizard → Anypoint Studio → Packaged Application
You can monitor the import progress in the bottom right corner of the Anypoint Studio.
Once import completes, a project gets created in Anypoint Studio with the configurations packaged in the JAR file.
In your Anypoint Studio left sidebar, navigate to the src/main/mule and click on the xml file.
Click on Message Flow tab in the center screen.


In your new project that got created (default name: stage2b-customer-inference-mcpclient) - we need to update two variables.
In the left sidebar, click on /src/main/resources/config.properties
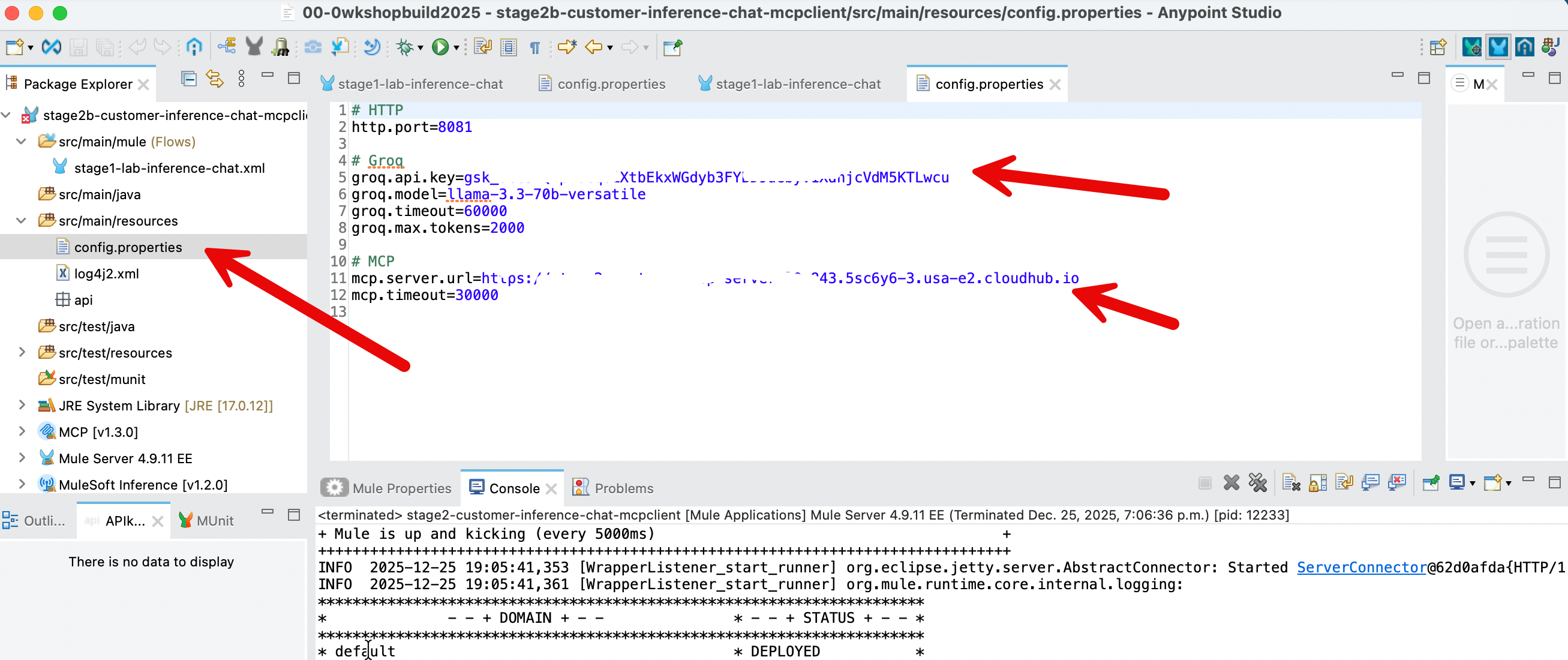
Update the value of 4 property values:

- Put in the
groq.timeoutandmcp.timeoutvalues as shown above. - The value for
groq.api.keyis the api key that you got when you had signed up in groq. - The value of the variable
mcp.server.urlis the public endpoint of your mcp server that you deployed on CloudHub in the Stage 2a above. Note: please do not include forward slash at the end.
After you have updated the property values - File → Save
In Anypoint Studio, right click on your project (Stage2b....) in the left sidebar → Run As → Mule Application
Once the build and run completes in the Anypoint Studio, you should see the following screen.
Your Inference Connector with MCP client is live locally. Let’s fine tune it - see the challenge section below.
Challenge: Controlling When the Agent Uses MCP
Fine-tune your Gen AI capability so that:
- Parts / Inventory / status / availability questions always use MCP
- General or creative questions never use MCP
Update the system instructions in the element [MCP] Tooling so the agent follows explicit rules, for example:
- If the user asks about inventory, stock, availability, status, parts, materials → must use MCP
- If the question is general knowledge, creative, or explanatory → must not use MCP

Hint: Click on the [MCP]Tooling element - replace the current text in the Instructions field (not the template field) with this block to enforce your rules:
You are an enterprise AI assistant.
You MUST follow these rules exactly:
1. If the user question involves parts, inventory, availability, status, stock levels, recalls, or operational data:
- You MUST use an MCP tool to retrieve authoritative information.
- Do NOT answer from general knowledge or assumptions.
2. If the user question is general, conceptual, explanatory, or creative:
- You MUST NOT use MCP tools.
- Answer directly using your model knowledge.
3. MCP tools are ONLY for authoritative, enterprise, or up-to-date information.
Never use MCP for opinions, explanations, examples, or creative writing.
4. Tool usage must be invisible to the user unless explicitly requested.
Follow these rules strictly.Test the different scenarios - however first we need to ‘compile’ our application again:
- You also need to go to CloudHub and stop/start the MCP server that you deployed there in Stage 2a. The MCP server needs about 5 minutes to stop and then 5 minutes to start. Please wait for the MCP server to start before deploying Stage 2b.
- In Anypoint Studio, right click on your project (Stage2b....) in the left sidebar → Run As → Mule Application.
Once the MCP server starts in CloudhHub and your Stage2b app gets deployed in Anypoint Studio, in your windows shell, run the following two commands:
Local test (LLM only – no MCP should run):
curl -X POST http://localhost:8081/prompt -H "Content-Type: application/json" -d "{\"prompt\":\"Write a short haiku about integration.\"}"Local test (forces MCP tool invocation):
curl -X POST http://localhost:8081/prompt -H "Content-Type: application/json" -d "{\"prompt\":\"Check the inventory status for Heat Resistant polymer housing.\"}"What we learned: We learned to shape agent behavior using precise prompts and enforce the use of authoritative enterprise data for sensitive queries. By implementing a smart routing pattern, you also prevented unnecessary tool executions, ensuring your agent remains both grounded and performant.
Let’s now deploy your Stage2b app to CloudHub.
Right click your project → Anypoint Platform → Deploy to CloudHub
You may be asked to authenticate in an embedded browser that opens in Anypoint Studio. Sign in with your Mule trial account.
Select Sandbox when asked in the next screen after authentication
Click the Properties tab and fill in the values as in your config.properties file in your project - except for http.port.
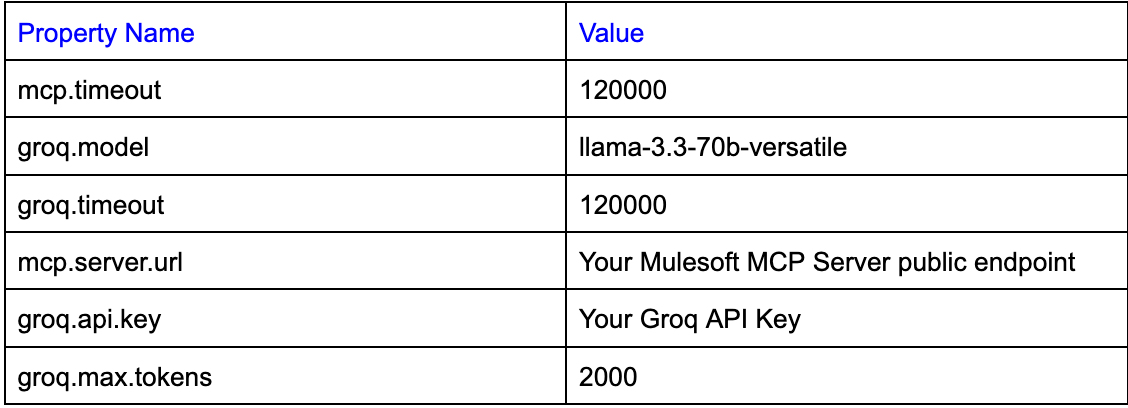
groq.api.key={your key here}
groq.model=llama-3.3-70b-versatile
groq.timeout=120000
groq.max.tokens=2000
mcp.server.url={your MCP Server URL here}
mcp.timeout=120000Please see screenshot below.
- Please especially note the url format for the
mcp.server.urlproperty. There is no forward slash at the end. - Please make sure both
mcp.timeoutandgroq.timeoutare set to 120000

Press Deploy Application.
Now go to mulesoft.com → sign in → Runtime Manager - You would see your newly deployed application running there.

Let’s test your CloudHub deployment.
Click on your application and then in the application’s page - copy the Public Endpoint (top right on the application’s page).
Replace the url in the following command with your Public Endpoint.
CloudHub test (LLM only – no MCP should run):
curl -X POST https://stage2b-customer-inference-chat-mcpclient-xyz.5sc6y6-4.usa-e2.cloudhub.io/prompt -H "Content-Type: application/json" -d "{\"prompt\":\"Write a short haiku about integration.\"}"Replace the url in the following commands with your Public Endpoint.
CloudHub test (forces MCP tool invocation):
curl -X POST https://stage2b-customer-inference-chat-mcpclient-xyz6-4.usa-e2.cloudhub.io/prompt -H "Content-Type: application/json" -d "{\"prompt\":\"Check the inventory status for Heat Resistant polymer housing.\"}"If you see errors - please restart on CloudHub both your servers - your mcp server (deployed in Stage 2a) and your Inference Connector’s MCP client (deployed in Stage 2b).
We have built a UI-based client you can use to test your headless agentic capability.
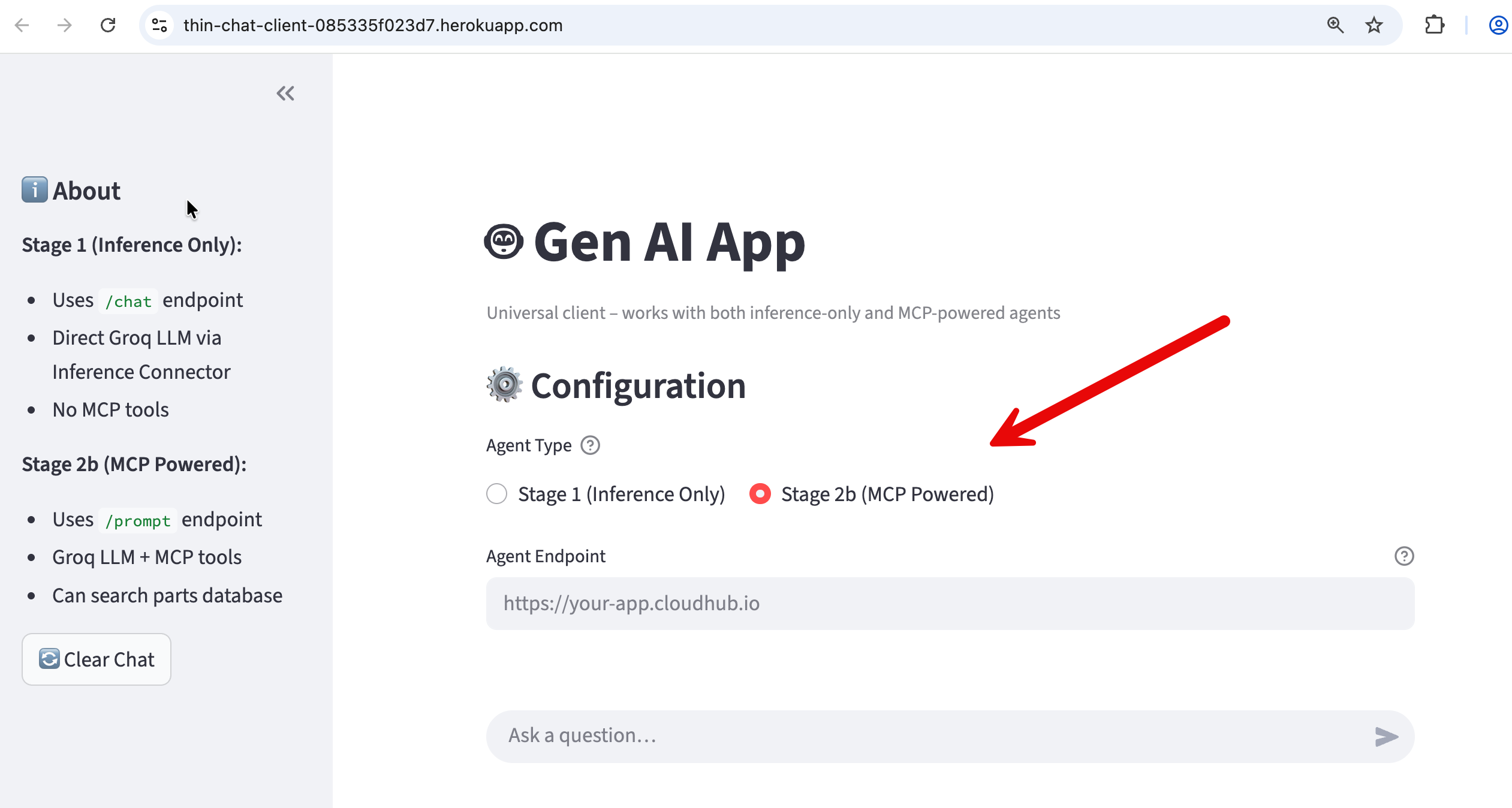
https://thin-chat-client-085335f023d7.herokuapp.com/
- Enter your stage2b cloudhub public endpoint in the "Agent Endpoint (CloudHub)" box.
- Select Stage 2b (MCP Powered) as shown in the screenshot.
If you ask a generic question (“Tell me about my parts inventory“) the agent transparently fetches the parts inventory from the MCP server database and serves it to you. If you ask a general question (”Tell me a joke“) - the agent responds without making a call to the MCP server.
This app written in Python (and using Streamlit library for UI) is intentionally a thin client: it performs no reasoning, does not invoke MCP, and contains no agent logic of its own. Its sole responsibility is to send a simple { "prompt": "…" } request, receive a fully formed response, and present it conversationally.
All intelligence and decision-making remain centralized in the Stage 2b capability—specifically within the Mule Inference Connector (which includes a MCP client), the Groq LLM, and the MCP server. This clean separation reinforces a key architectural principle for customers and attendees: the UI is fully interchangeable (Streamlit, Slack, Salesforce, mobile, and more), while agentic behavior and enterprise grounding live entirely within Mule and the AI infrastructure.
What we explored today is the core of every serious AI system: a reasoning layer that knows when it does not know, and knows how to ask the right system for truth.
What You Accomplished
We built a foundational agentic capability that can be embedded into different architectures and user experiences.
Specifically, we implemented a reasoning-and-action capability using MuleSoft that combines a large language model (Groq) with optional access to external, authoritative data sources via the Model Context Protocol (MCP). This capability can receive a user question, evaluate whether the answer can be generated from the model’s knowledge alone, and—when required—retrieve up-to-date or enterprise-specific information from external systems.
When external data is needed, the capability dynamically invokes an MCP server, retrieves the relevant information (for example, documents hosted in a GitHub Gist or other enterprise repositories), and feeds that information back into the language model to produce a final, grounded response. The result is a single, coherent answer returned to the caller, without exposing the underlying tool calls or data-fetching steps unless explicitly required.
This module uses MCP as a required dependency for clarity. Production agents invoke MCP on demand and degrade gracefully when grounding services are unavailable.
At this stage, the work demonstrates agent-like behavior, but it is intentionally delivered as a headless capability, not a full agent. There is no long-term memory, goal management, user identity, or autonomous task loop. Those elements can be added later by embedding this capability inside a chat UI, workflow engine, digital agent platform, or multi-agent system.
In short, we built the core reasoning, tool-selection, and grounding mechanism that real-world AI agents rely on—cleanly separated from presentation, orchestration, and experience layers. This separation is what makes the capability reusable, testable, and production-ready.
How This Fits into the Bigger System
In the full architecture, different responsibilities are clearly separated:
- Agents reason and act.
- MCP servers provide real-time or frequently changing authoritative knowledge.
- RAG (via Data 360 and Agentforce) provides governed enterprise memory and operational data.
- Mule Agent Fabric decides which agent or knowledge source to use and in what order.
Stage 2 focuses only on the first half of this picture: grounding an agent using MCP. Later stages will show how this connects to Agentforce and full multi-agent orchestration.
Appendix - I
Anatomy Of Our Mule Gen AI Agentic Application
Stage 2a: Anatomy of the Mule MCP Server
This Mule application represents the "Hands" of your agentic system. It does not "think" or "reason." Its sole purpose is to expose a specific capability (a Tool) that an AI agent can discover and execute on demand.
Here is the breakdown of the two distinct flows.
1. The Health Check Flow (health-check-flow)
This is a standard DevOps pattern. It provides a dedicated endpoint (/health) on port 8082. This allows monitoring tools or a human operator to verify the Mule app is running without triggering the complex MCP protocol logic.
Components:
- HTTP Listener: configured to listen on port
8082. - Transform Message: Hardcoded to return a simple JSON status:
{"status": "ok", "service": "mcp-authoritative-server"}
2. The MCP Tool Flow (mcp-tool-flow)
This flow defines the "Tool" pattern we discussed. It fetches live data from an external system (GitHub Gist) and serves it to the Agent.
Key Components:
MCP Tool Listener (The Trigger):
- What it does: This is the most critical element. Unlike a standard API that waits for a GET/POST request, this listener registers a tool named
get_authoritative_live_referencewith the MCP Server. - The "Contract": It includes a Description field ("Fetches the real-time Authoritative Live Reference..."). The AI reads this description to decide when to call this tool.
HTTP Request (The Action):
- What it does: When the tool is triggered, this component performs the actual work. It makes a
GETrequest to the raw Gist URL. This ensures we are always fetching the absolute latest version of the data, satisfying our "freshness" requirement.
Transform Message (The Output):
- What it does: It converts the raw data (which might be JSON, Markdown, or HTML) into
text/plain. This plain text format is optimized for the LLM to read and synthesize into an answer.
How We Built the MCP Server with MuleSoft
While the workshop provides a pre-packaged JAR to save time, understanding how to build this from scratch is essential if you want to apply this design to your own enterprise systems.
When designing an MCP Server (Stage 2a), shift your mindset from orchestrating workflows to exposing capabilities.
Instead of predicting the user's journey and building an API to match it (Outside-In), we wrap our backend's atomic functions in clearly described Tools (Inside-Out). We provide the raw "lego blocks" of your system—like "Fetch Reference" or "Check Health"—and trust the AI Agent to decide how and when to assemble them to solve the user's problem.
The fundamental shift in Agentic design (including MCP server design) is moving from a Syntactic Contract to a Semantic Contract. In traditional integration, you define the syntax (endpoints and data structures) and rely on human developers to read documentation to understand the business logic. In an MCP-based design, you embed that meaning directly into the interface via natural language descriptions, enabling the AI Agent to autonomously understand not just how to call a service, but why and when it is appropriate to use it.
Step 1: Configure Global Elements
Before building the flows, you must set up the connections.
- HTTP Listeners:
- Create a listener config named
HTTP_Listener_MCPon port 8081 (This will carry the SSE traffic). - Create a listener config named
HTTP_Listener_Healthon port 8082 (For the health check).
- Create a listener config named
- MCP Server Config:
- Search for "MCP" in the palette and add the MCP Server Configuration.
- Link it: Set the
Listener ConfigtoHTTP_Listener_MCP. This tells the MCP server to use port 8081 for itsssehandshake. - Name it: Set the Server Name to
authoritative-ref-serverand version to1.0.0.
- HTTP Request Config:
- Set up a configuration pointing to
gist.githubusercontent.comon port 443 (HTTPS).
- Set up a configuration pointing to
Step 2: Build the Health Check Flow
- Drag an HTTP Listener to the canvas.
- Connector Config: Select
HTTP_Listener_Health. - Path: Set to
/health.
- Connector Config: Select
- Drag a Transform Message component after the listener.
- Output: Paste the JSON payload:
{"status": "ok", ...}.
- Output: Paste the JSON payload:
Step 3: Build the MCP Tool Flow (The Core Logic)
- Add the Trigger:
- Drag the MCP Tool Listener (from the MCP module in the palette) to the source section of a new flow.
- Config Reference: Select the
MCP_Serverglobal config you created in Step 1. - Tool Name: Enter
get_authoritative_live_reference. (Note: Use snake_case as this is standard for LLM tool naming). - Description: Enter: "Fetches the real-time Authoritative Live Reference Database (Status, Recalls, Inventory) directly from the system of record." (Be precise; this is the prompt the AI reads).
- Parameters: Leave the schema as an empty object
{}because this tool requires no input arguments.
- Add the Action:
- Drag an HTTP Request component.
- Method:
GET. - URL: Paste the full raw Gist URL:
https://gist.githubusercontent.com/lightningexperience/1ad6005e89b050b1d0ab2e5de1350bb1/raw/
- Format the Output:
- Drag a Transform Message component to the end.
- Script:
%dw 2.0
output text/plain
---
payloadOnce deployed, this application will wait silently. It does not do anything until an Agent connects via SSE on port 8081 and explicitly requests the get_authoritative_live_reference tool.
Stage 2b: Anatomy of the Mule Inference Connector & MCP Client
This stage represents the transition from a simple chatbot (Stage 1) to a Grounded Agent. The flow connects the LLM (Groq) to an MCP Server, allowing the AI to fetch real-time data before answering the user.
The Grounded Agent Flow
In this stage, the application doesn't just "imagine" answers; it has access to tools. The logic introduces a decision branch: did the AI use a tool to get data, or did it answer from general knowledge?
1. The Core Logic: "Groq Agent with MCP Tools"
This is the heart of the flow (labeled ms-inference:mcp-tools-native-template in the XML).
- What it does: It sends the user prompt to the LLM (Groq) along with a list of available tools from the
MCP_Client_CloudHubconfig. - The "Brain": The LLM decides intelligently:
- Does this question require live data? (e.g., "Check inventory for part X"). → Call the MCP Tool.
- Is this general chit-chat? (e.g., "Write a poem"). → Answer directly.
2. The Decision Router (Choice)
Immediately after the agent runs, the flow hits a Choice Router (doc:name="Did Tools Run?"). This is critical for handling the response format.
#[payload.toolsExecutionReport? and sizeOf(payload.toolsExecutionReport) > 0]This Mule DataWeave expression checks if the payload contains a "tools execution report." If it does, it means the AI accessed external data.
Note: DataWeave is MuleSoft's scripting language designed specifically for querying and transforming data between different formats, such as JSON, XML, and CSV.
Path A: When Tools Are Used (The "Summarize" Path)
If the condition is True (top path in the screenshot), the flow performs a Retrieval-Augmented Generation (RAG) pattern:
- Prepare Summary Prompt: The flow takes the raw, ugly JSON data returned by the tool and wraps it in a new prompt for the AI.
- System Instruction: "You are a helpful assistant. You have just retrieved data from a tool... answer the User's original Question concisely."
- Summarize Answer: It calls the LLM (
ms-inference:chat-completions) a second time. This time, the AI reads the raw data and converts it into a human-friendly sentence. - Format Final Answer: Cleans up the result into a standard JSON response for the API caller.
DataWeave Explanation (Prepare Summary Prompt)
This script is the "bridge" between the raw data the tool found and the AI's brain. It formats the data so the AI can read it.
%dw 2.0
output application/json
[
{
"role": "system",
"content": "You are a helpful assistant. You have just retrieved data from a tool. Use the provided Tool Data to answer the User's original Question concisely. Do not mention the JSON structure."
},
{
"role": "user",
"content": "User Question: " ++ vars.userPrompt ++ "\n\nTool Data: " ++ write(payload, "application/json")
}
]Line-by-Line Breakdown:
output application/json: This tells Mule to output a JSON object, which is exactly what the Chat Completions connector expects as input.
The Array [...]: We are building a list of messages to send to the AI. This follows the standard "Chat History" format (System message first, then User message).
The System Role:
"role": "system": Defines the persona.- Why strict instructions? The text "Do not mention the JSON structure" prevents the AI from saying awkward things like "According to the JSON object key 'price'..." instead of just "The price is $10."
The User Role:
"role": "user": Represents the current query.- The Concatenation (
++): This is the magic part. It stitches together two things:vars.userPrompt: The question the user originally asked (e.g., "What is the status of order 123?").write(payload, "application/json"): Thepayloadcurrently holds the raw answer from the MCP Tool. Thewrite()function turns that raw object into a text string so it can be inserted into the prompt.
Path B: Default (The "Direct" Path)
If the condition is False (bottom path in the screenshot):
- Format Direct Answer: The AI didn't need tools. It simply passes the AI's direct textual response back to the user without any extra processing.
How We Built This Flow: Stage 2b: Mule Inference Connector + MCP Client
This guide reconstructs the Stage 2b flow.
Prerequisites
Make sure your Anypoint Studio palette has the following modules installed (visible in your screenshot):
- MuleSoft Inference (for Groq/LLM)
- MCP (Model Context Protocol)
- HTTP (Standard)
Step 1: Configure Global Elements
Before building the flow, set up the connections.
- HTTP Listener Config: Set simple host
0.0.0.0and port${http.port}. - Groq Inference Config:
- Add a
Text Generation Config. - Select Groq Connection.
- Set API Key to
${groq.api.key}and Model Name to${groq.model}.
- Add a
- MCP Client Config:
- Search for "MCP Client Config".
- Set Client Name to
mule-inference-client. - Connection Type: SSE Client Connection.
- Server URL:
${mcp.server.url}(This points to your external Python/Node MCP server).
Step 2: Build the Main Flow
- HTTP Listener:
- Drag into canvas. Path:
/prompt. Method:POST.
- Drag into canvas. Path:
- Set Variable:
- Name:
userPrompt. - Value:
#[payload.prompt]. (This saves the user's question for later use in the DataWeave script above).
- Name:
- Groq Agent with MCP Tools:
- Drag in the component
mcp-tools-native-templatefrom the MuleSoft Inference palette. - Config Ref: Select your
Groq_Text_Generation_Config. - MCP Config: Add a reference to your
MCP_Client_CloudHub. - Instructions: Paste: "Answer the user's question... If answering requires company-specific live parts information use the available MCP tools.".
- Drag in the component
Step 3: The Logic Router
- Choice Router:
- Drag a Choice component after the Groq Agent.
- Top Path (When) Expression:
#[payload.toolsExecutionReport? and sizeOf(payload.toolsExecutionReport) > 0](This logic means: "Did we actually run a tool?").
Step 4: The "Tools Used" Path (Top Branch)
- Transform Message (Prepare Summary):
- Paste the DataWeave script explained in Part 1 here.
- Chat Completions (Summarize):
- Drag in
Chat completionsfrom the Inference palette. - Set Messages to
#[payload](passing the script output to the AI).
- Drag in
- Logger (Optional):
- Log the raw response:
#['Groq Raw Response: ' ++ write(payload, 'application/json')].
- Log the raw response:
- Transform Message (Final Format):
- Clean up the AI's response to valid JSON:
%dw 2.0
output application/json
{ "answer": payload.choices[0].message.content default "Error" }Step 5: The "Direct Answer" Path (Default Branch)
- Transform Message:
- Just pass the payload through:
Note: In the "Default" case, the payload from the Groq Agent is already the plain text answer because no tools were triggered.
Summary
This stage transforms our standard chatbot into an intelligent "Grounded Agent" capable of accessing real-time business data to solve actual customer problems. By integrating with the Model Context Protocol (MCP), the system now autonomously decides whether to answer a general question instantly or reach into our backend systems to retrieve specific, live information (like inventory or order status). This logic ensures that AI responses are not just conversational but factually accurate and based on current company records, automatically converting complex system data into clear, human-friendly answers for the user.
APPENDIX - II
How Our Work Here Fits in With Broker Orchestrated Multi-Agent System
RAG provides enterprise memory, MCP provides real-time authority, agents reason and act — and Mule Fabric decides who speaks, when, and why.
Typically, Agents do not own corporate knowledge. They consult authoritative systems (e.g., RAG (Vector Databases), MCP) when they need the latest truth.
01. Architecture Plan — System Structure Plan
In our envisioned architecture, Mule Agent Fabric (Broker) is the central orchestration layer that coordinates two specialized agents, each with a clearly bounded responsibility.
The Custom Agent is optimized for fast reasoning and external intelligence. It is integrated with an MCP client, which allows it to query an MCP server that exposes authoritative, frequently changing information (for example, live advisories, updates, or reference catalogs). The MCP server is treated as a real-time source of truth and is queried on demand rather than indexed (in a vector database).
The Agentforce Agent is optimized for enterprise operations. It is connected to Data 360 (formerly Data Cloud) and uses RAG to reason over governed, indexed enterprise knowledge such as documents, historical records, and operational data. It is also responsible for taking Salesforce actions (cases, updates, workflows) in a policy-safe way.
Importantly, the agents do not coordinate with each other directly. All routing, sequencing, and authority decisions are handled by the Mule broker.
Comparison of the MCP Client - Server-LLM Flow with Mule Agent Fabric Broker Orchestration
- Planning in design occurs within a single agent and is limited to deciding whether external data or tools are required to answer the current request. It is a short-lived, per-request reasoning step executed by the LLM through the Inference Connector, with no persistent memory, no authority to route work, and no awareness of other agents.
- Fabric Broker planning operates at a fundamentally different level: it coordinates between multiple autonomous agents, makes durable routing and delegation decisions, applies policy and governance, and manages long-lived, cross-agent workflows.
In short, Inference-based planning decides how one agent should act right now, while Fabric Broker decides which agent should act and how work flows across an agent ecosystem.
02. Use Case Plan — Why MCP and RAG Both Exist
Enterprises typically have two different kinds of knowledge needs:
- Enterprise memory — stable, historical, and governed information such as manuals, policies, contracts, and operational records. This is best handled through RAG inside Agentforce, where data is indexed, secured, and audited.
- Real-time or latest authority — information that changes frequently or is owned by an external system, such as advisories, updates, notices, or live reference data. This should not be indexed or cached. Instead, it must be queried at the moment it is needed. This is where MCP servers are used.
In this use case, when a user asks questions like “Are there any latest updates?” or “Has anything changed recently?”, the system treats that as a freshness requirement, not just a data source question. The MCP server provides the authoritative answer, while Agentforce remains the system of record for enterprise data and actions.
This pattern is universal and applies across industries (manufacturing, finance, healthcare, telecom), regardless of the specific data being queried.
MCP works only when three conditions align:
- a system of record exists,
- the question maps to a precise query,
- and the answer is a retrievable fact—making it mandatory for runtime verification needs like "Can I ship this order?" or "What is the current balance?" where exactness, freshness, and action-driving answers are critical.
However, when response requires understanding and interpretation rather than lookup—such as synthesizing themes across 50 contracts, summarizing customer complaints, or discovering what questions to ask—RAG is necessary because no single retrievable fact exists, and the goal is faithful representation without hallucination.
The clean rule: use MCP when correctness depends on data being current and authoritative (checking the live system before acting), and use RAG when correctness depends on data being understood and interpreted (reading the policy manual carefully)—both are forms of correct response serving different needs, and enterprise AI systems typically need both.
03. Orchestration Logic Plan — How Decisions Are Made
How MCP & RAG fit in with the Mule Broker Orchestration.
The key orchestration concept is temporal authority. The Mule broker does not simply route based on “general vs support.” Instead, it evaluates whether the user’s question requires latest or real-time information.
- If the user explicitly or implicitly asks for latest, current, recent, updated, or real-time information, the broker routes the request to the Custom Agent, which queries the MCP server.
- If the user asks about enterprise records, historical knowledge, or needs an operational action (cases, updates, workflows), the broker routes the request to Agentforce.
- If both are required, the broker sequences the interaction:
- First, retrieve authoritative real-time context via MCP.
- Then, pass that context to Agentforce to reason over enterprise data or take action.
This orchestration logic lives entirely in the Mule broker instructions, not inside agent prompts or code. As a result, behavior can be changed, extended, or audited without redeploying agents.
Understanding MCP: Beyond API Wrappers
While MCP can be thought of as "REST with a standardized contract," its real power lies in how it transforms tool integration from procedural function calls into declarative capabilities that AI agents can discover and orchestrate autonomously.
Unlike traditional APIs, which expose fixed endpoints for specific user flows (for example, GET /inventory), an MCP server exposes tools instead of endpoints. In this module, we exposed a single tool that fetches a document from a GitHub Gist. We did not define a workflow or prescribe when the tool should be used; we only declared the capability.
How the data flow happens in our Flow: MCP Client-Server-LLM interaction
- Before any user prompt is processed, the client application (the Mule inference connector acting as the MCP client) already knows where the MCP server is, but it does not know what tools it exposes.
- To learn that, the client establishes an MCP session by opening the /sse connection to the MCP server.
- As part of that SSE handshake, the MCP server immediately sends protocol events that describe its capabilities — including the list of available tools, their names, and their input/output schemas — and also provides the session-specific message endpoint. The client caches this tool metadata for the lifetime of the session.
- Later, if a user asks “give me parts information,” the client includes those tool descriptions in the context it sends to the Groq LLM.
- The LLM does not discover tools dynamically on its own; it reasons over the tool descriptions that the client has already obtained from the MCP server via SSE, decides whether a tool is relevant, and signals back to the client which tool to invoke.
How do you add multiple MCP tools to the MCP client?
Multiple MCP servers are wired by adding parallel MCP Tooling elements at the same decision point — not by adding routes, subflows, or orchestration logic.
In context of our project app, the second MCP server is added by placing a second [MCP] Tooling element in the same flow, immediately after the same “Set User Prompt” step, exactly as shown in the diagram. Both MCP Tooling components consume the same input context (the prepared user prompt) and both write their results back into the same payload structure that is later evaluated by the “Did Tools Run?” Choice.
The only difference between the two tooling elements is that each one references a different MCP Client global configuration, pointing to a different MCP server. There is no subflow, no chaining between tooling elements, and no sequencing logic added.
At runtime, the agent reasons over the combined tool registry exposed by all MCP servers, decides which specific tool to invoke, and Mule executes the corresponding MCP Tooling call; the Choice router then behaves exactly as before, checking whether any tool was executed and continuing downstream unchanged.
In the following diagram, only one MCP Tooling element is executed per request; the agent selects which tool to invoke at runtime.

Commercial MCP clients (such as Cursor or Claude) abstract this wiring entirely by exposing MCP server configuration through their settings UI. For example, in Cursor, adding another MCP server (such as the one built in this workshop) is done by updating the MCP configuration in Cursor Settings. In our Mule-based implementation, this same configuration is expressed explicitly in the flow by adding another MCP client configuration and tooling element, making the wiring visible and fully governed.
What happens when there are multiple MCP servers and multiple tools registered with a MCP client?
Unlike traditional API design, there is no equivalent of “Mule APIkit path routing” for tools; tool selection is entirely semantic and occurs at runtime inside the LLM’s reasoning step.
In practice, adding multiple MCP tools does not require additional routing logic or orchestration flows.
- Each tool is exposed by defining an additional MCP Tool Listener, typically as its own Mule flow, with a unique Tool Name and a clear natural-language Description.
- All tools registered by the MCP server are automatically discovered by the MCP client during the SSE handshake and presented to the LLM as a list of available capabilities.
- The agent does not select tools based on URLs, priorities, or conditional routing; instead, the LLM chooses which tool to invoke at runtime by reasoning over the tool descriptions and the user’s intent.
- Mule’s role is simply to expose these tools reliably and execute them when called. This means scaling from one tool to many is additive rather than architectural: you add new tools as independent capabilities, and the agent dynamically decides when and whether to use them without any changes to the orchestration logic.
The protocol standardizes everything - from JSON-RPC request/response formats to tool discovery patterns - meaning you write one MCP client that works with any MCP server, whether it's providing weather data, database queries, or file operations. For example any MCP client (e.g., Cursor AI Agent) can talk to the MCP server you deployed in this workshop.
MCP uses persistent bidirectional communication (Server-Sent Events) rather than REST's request-response model.
In Stage 2a you will see this difference vividly during the testing phase.
- When you use curl to test a standard REST API, you get a response and the connection closes.
- In this lab, when you target the
/sseendpoint, your terminal will appear to "hang". This is not a bug; it is the SSE handshake in action. You will see the server verify the connection and issue a sessionId. This open channel is the "persistent connection" that allows the server to push updates and maintain the conversational state required for agentic workflows.
What Makes MCP Special for AI Workflows
Instead of writing custom glue logic with hardcoded decision trees, MCP enables the LLM to reason about tools.
Every MCP server self-describes its capabilities through a mandatory tools/list discovery method, declaring available tools with precise schemas that tell clients exactly what parameters are needed without parsing separate documentation.
This schema-driven interaction, combined with MCP's persistent bidirectional communication pattern (unlike REST's request-response), creates an environment optimized for how LLMs actually work - they've been trained on millions of function call examples and reliably generate structured tool calls when presented with clear schemas. The result is true reasoning-driven automation where AI agents can reflect on their tool usage, chain multiple calls together, and adapt their strategy dynamically rather than following predetermined workflows.
In the section 2a - we build and deploy a MCP server. While you won't see the LLM read the schema until Stage 2b, you will deploy the MCP server with a pre-packaged JAR that contains the mcp:tool-listener. This listener automatically handles the tools/list discovery requests mentioned in your text.
By deploying your MCP server to CloudHub, you are creating a "live" authority that conforms to the JSON-RPC standard, ready to be discovered by any compliant client—whether it's the Mule Agent you build next, or a desktop app like Claude.
MCP Server: Tools & Resources
In developing an MCP server, you must decide on the appropriate design pattern, as the protocol allows data sources to be exposed as Tools and/or Resources. In our project, we implemented the Gist data source specifically as an MCP Tool
Implementing our MCP server with Tools instead of Resources was a deliberate architectural choice to prioritize immediate freshness, but it represents just one valid design pattern for this use case.
Alternatively, we could have exposed the Gist document as a Resource—passive background context that the client preloads and caches—paired with a separate Search Tool to filter that content based on specific user queries.
While that hybrid approach is powerful for managing stable reference data, our tool-only design enforces a strict "live query" model, ensuring the agent retrieves the absolute latest advisories on-demand without the complexity of managing client-side state or deciding when to refresh cached resources.
Interacting with MCP Server: MCP Client Architecture
In a traditional REST API, the client already knows everything it needs up front: the endpoint URL, the request shape, and the response pattern. That’s why a single curl or a GET/POST command works—you are calling a fixed, globally addressable endpoint.
MCP deliberately does not work this way. An MCP server does not expose a permanent “tool endpoint” that you can call directly.
Instead, MCP is a two-step protocol.
- First, the client opens a Server-Sent Events (SSE) connection. This is not just a transport detail—it is the protocol’s handshake. Through this live connection, the MCP server announces what it can do and, crucially, returns a session-specific message endpoint (for example
/message?sessionId=abc123). - Only after this step can the client invoke tools, and those tool calls must be sent to the dynamically issued endpoint. You cannot guess this endpoint, hardcode it, or skip the SSE step—the server will correctly reject such calls.
Remember the command we gave to our MCP CloudHub endpoint and the response we got (it seemed to be hanging).

What this does:
-Nflag keeps the connection open for SSE streaming- Calls the
/sseendpoint - Sends MCP JSON-RPC request to list available tools
What we get back from the MCP server is not a tool response; it's the protocol handshake. The server is telling us it has created a session for this connection (event: endpoint) and it returns a session-specific message endpoint (data: /message?sessionId=19991db7-...). That endpoint did not exist before the SSE connection, it is unique to this session, and it is the only place where tool invocations must be sent.
At this stage, the server does not list tools or capabilities yet—tool discovery and invocation happen only after the client sends an initialize request with the provided session ID, and then in the third step, sends tools/list or tools/call messages to the issued endpoint.
The MCP protocol's multi-step handshake (SSE connection → session creation → initialize → tool operations) requires a stateful SSE client that maintains persistent connections with active event listeners. The Mule MCP Connector uses asynchronous SSE client libraries that hold the connection open, register event handlers, and process incoming SSE events as they arrive on the stream.
We can not directly use REST paradigms or tools - for example curl is fundamentally synchronous and stateless - while MCP server expects all requests and responses to flow through the same persistent SSE connection with proper event-driven handling, which curl's request-response model cannot replicate. In short, REST lets you call a known endpoint once. MCP requires you to first establish a live session, then act within it. That extra step is not overhead—it’s the foundation that makes MCP dynamic, safe, and agent-native.
Server-Sent Events (SSE) is a protocol built on top of HTTP. SSE is used in MCP because the protocol is not just about sending requests; it's about maintaining a live conversational context between client and server. SSE allows the server to push structured events to the client over time: capability announcements, session state, and other protocol-level signals.
MCP Transport Options: MCP supports three transport mechanisms for client-server communication.
- SSE (Server-Sent Events) establishes an HTTP connection to a remote server's
/sseendpoint, where the server pushes JSON-RPC responses as events over a persistent HTTP stream—this is used for network-deployed servers like CloudHub or web-accessible MCP servers. - stdio (Standard Input/Output) spawns the MCP server as a local subprocess and exchanges JSON-RPC messages through stdin/stdout pipes, enabling the client to directly control the server process lifecycle—this is used by desktop applications like Claude Desktop to connect to locally-installed MCP servers (e.g., filesystem tools, local databases).
- Streamable is a framework-specific abstraction layer (like the Mule MCP Connector's internal interface) that provides a unified streaming API over either SSE or stdio, allowing application code to interact with MCP servers through a consistent event-driven interface regardless of the underlying transport.
The choice between SSE and stdio is deployment-driven: remote servers require SSE for network communication, while local servers use stdio for inter-process communication on the same machine.
APPENDIX - III
Resources
Mule MCP Connector on Exchange: https://www.mulesoft.com/exchange/com.mulesoft.connectors/mule-mcp-connector/minor/1.3/pages/home/
Mule MCP Connector documentation: https://docs.mulesoft.com/mcp-connector/latest/mcp-connector-studio
Technical Design
Use Case
We are building a single, real-world AI agent that:
- Answers general questions using an LLM (Groq)
- Decides at runtime whether the answer can be generated from model knowledge alone
- If external or up-to-date information is required, retrieves it from enterprise data sources (for example, documents in a GitHub Gist)
- Incorporates that retrieved information into the final answer
- Responds to the user as a single continuous conversation
From the user’s perspective, there is one agent. Tool usage is invisible unless explicitly requested.
Design Overview
The solution consists of two Mule applications:
A. Agent Application (Stage 2b – Real Agent)
This application is the agent. It contains:
- Mule Inference Connector (calling Groq)
- Decision logic to determine whether tools are needed
- MCP client to invoke tools when required
- Orchestration logic to combine reasoning and tool results
- A single
/promptentry point for users
The agent performs three reasoning steps using the same LLM:
- Planning – Decide whether external data is required
- Action – Select and execute MCP tools (if needed)
- Response – Generate the final answer using tool results or general knowledge
There is no separate orchestration service and no agent-to-agent routing at this stage.
B. MCP Server Application (Stage 2a – Tools)
This application hosts enterprise tools and data access:
- Exposes tools using MCP (
mcp:tool-listener) - Encapsulates access to systems such as documents, APIs, or ERP systems
- Has no knowledge of prompts, LLMs, or reasoning
- Is stateless and reusable across agents
The agent application calls this app only when grounding is required.
Key Architectural Principle
- The Inference Connector performs reasoning.
- The MCP Server performs actions.
- Mule flows orchestrate when and how they interact.
This separation keeps the design deterministic, auditable, and extensible.
Environments
- Latest/real-time advisory data source. Typically a data source like this would be updated frequently by the corporation.: Public REST endpoint (GIST) for the workshop: https://gist.github.com/lightningexperience/1ad6005e89b050b1d0ab2e5de1350bb1
- Mule trial account
- Mule VM for Anypoint Studio tools access
- Heroku trial account
Gotchas
This is fully expected in your implementation.
Your MCP server is fully functional as deployed. MCP clients interact exclusively through the /sse endpoint, which is working correctly on CloudHub. The /health endpoint is not part of the MCP protocol and is only provided as a convenience for local monitoring and debugging.
Locally, /health is accessible on port 8082, but CloudHub does not expose that port externally, which is why the remote health check fails. Since MCP clients never call /health, no changes are required.
If you later decide to support remote health monitoring, you can expose the /health endpoint on port 8081 so it shares the same HTTP listener as /sse.
Thank You
Discussion
This workshop demonstrated the architecture of a Distributed Agentic System. We moved away from traditional "Request-Response" integration (where you hard-code every step) to "Reasoning-Action" integration (where the system decides the steps).
Here is the exact technical flow of the system we built:
1. The Trigger (The Client) It starts when you send a curl request to your local Mule app. This hits the HTTP Listener on port 8081. At this point, the Mule flow is just a "dumb pipe"—it has the user's question ("Check inventory"), but it has no idea what it means or how to answer it.
2. The Inference Connector: The flow passes the question to the MuleSoft Inference Connector. This connector is the bridge to the LLM (Large Language Model) hosted by Groq.
- The Prompt: The connector sends your text to Groq along with a list of definitions: "Here is the user's question, and by the way, I have a tool called
get_inventoryavailable if you need it." - The Reasoning: Groq analyzes the intent. It realizes, "I don't know the inventory count, so I must use that tool." Instead of answering the user, Groq sends a Tool Call Request back to MuleSoft.
3. MCP: This is where the magic happens. The Inference Connector sees Groq's request to run get_inventory.
- It doesn't run code locally or within it's training data or on the general web.
- Instead, it looks at your MCP Client Configuration.
- It uses a specialized protocol called Server-Sent Events (SSE) to securely "tunnel" that command over the internet to your remote Mule application running on CloudHub. This is the Model Context Protocol (MCP) in action—a standardized way for the "Brain" (Local) to control the "Hands" (Cloud).
4. The CloudHub Server: Your CloudHub server receives the signal. It executes the specific flow defined for get_inventory (which, in your case, retrieved the mock data file). It packages the result into a standardized JSON format (the "Tool Execution Report") and streams it back down the SSE tunnel to your local machine.
5. The Synthesis: Finally, your local Mule app has the raw data (the JSON dump). But it doesn't send that to the user.
- The Loop: Your flow detects the tool data and runs the Inference Connector a second time.
- The Context: It says to Groq: "Here is the user's original question, and here is the data the tool found. Please write the final answer."
- The Output: Groq reads the data, extracts the relevant facts ("95 units"), and generates the natural language sentence you see in your terminal.
You successfully built a loop where an AI model on one server "drove" a business process on a completely different server, using MuleSoft as the secure nervous system connecting them.